
- FIN-CLARIAH Research Infrastructure
A new national research infrastructure initiative FIN-CLARIAH for...
8.12.2021 8:12 by eahyvone - WarMemoirSampo published on December 3, 2021
A new “Sampo” application, “WarMemoirSampo”...
8.12.2021 8:04 by eahyvone - Five new SeCo papers accepted for the ISWC 2021
The 20th International Semantic Web Conference (ISWC 2021), the...
2.8.2021 6:53 by eahyvone
- Pieterjan Deckers, Eero Hyvönen, Michael Lewis, Eljas Oksanen, Heikki Rantala and Jouni Tuominen: ARCH-ON: A new ontological framework to describe archaeological objects for Digital Humanities research
- Eero Hyvönen, Annastiina Ahola, Petri Leskinen and Jouni Tuominen: Connecting Everything to Everything Else in a Cloud of Cultural Heritage Knowledge Graphs: SampoSampo Data Linking Service and Semantic Portal (Abstract)
- Petri Leskinen, Annastiina Ahola, Heikki Rantala, Jouni Tuominen and Eero Hyvönen: Consistency checking in a cloud of interlinked Cultural Heritage knowledge graphs – first results of using the SampoSampo data service and portal
- Petri Leskinen, Javier Ureña-Carrion, Jouni Tuominen, Mikko Kivelä, Eero Hyvönen: Knowledge Graphs and Data Services for Studying Historical Epistolary Data in Network Science on the Semantic Web
| FIN-CLARIAH Research Infrastructure: Developing a National Linked Open Data Infrastructure |
What is FIN-CLARIAH?
FIN-CLARIAH (2022-) is the premier Finnish digital research infrastructure for Social Sciences and Humanities (SSH) comprising two components,
- FIN-CLARIN (Finnish dimension of the Pan-European CLARIN infrastructure) and
- DARIAH-FI (Finnish collaborations with the Pan-European DARIAH infrastructure).
- Reach beyond processing of spoken standard Finnish into colloquial speech
- Cater to a broad range of SSH research needs for processing unstructured text
- Facilitate research based on metadata
The SSH field have not been at the forefront of the use of digital technology historically. However, this field in Finland has potential to enact such a transformation. The aim of FIN-CLARIAH is to ensure that such a digital transformation happens in an orderly fashion without duplication of efforts or reinventing the wheel.
FIN-CLARIAH involves all Finnish universities with research in SSH, including the coordinator University of Helsinki (Faculty of Humanities, Faculty of Social Sciences, and National Library), CSC – IT Center for Science Ltd., Aalto University, Tampere Universities, Universities of Eastern Finland, as well as the universities of Jyväskylä and Turku. In addition, FIN-CLARIAH has as project collaborators the universities of Vaasa and Oulu, the Institute for the Languages of Finland, and the National Archives of Finland.
Our Mission: Finnish Linked Open Data Infrastructure for Digital Humanities (LODI4DH)
The Aalto work in FIN-CLARIAH is related to maintaining and developing further the Linked Open Data Infrastructure for Digital Humanities in Finland (LODI4DH) in collaboration with the University of Helsinki (HELDIG, Faculty of Humanities) and other partners within the DARIAH-FI part of FIN-CLARIAH. The work includes also work on language infrastructures for spinning the Semantic Web and collaborations with FIN-CLARIN and CLARIN-EU. Our work is part of the cooperative partnership agreement between Aalto and DARIAH-EU.
The vision and results of our work are by 2024 are summarized in the presentation below, given at the DCMI 2024 conference, Toronto, Canada:
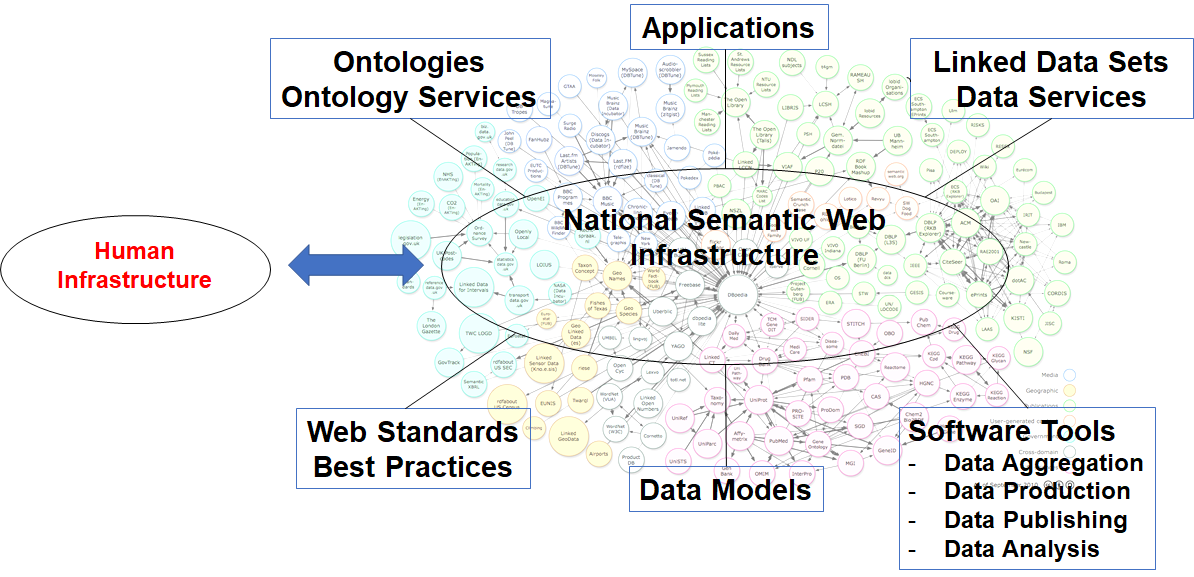
Figure 1 depicts elements that are needed in developing a national Semantic Web infrastructure according to the experiences reported in this paper.
The system is based on domain agnostic W3C Web Standards and Best Practices (on the left below in the figure) of
Since 2001, the SeCo group has been working on publishing and using linked data of Cultural Heritage on the Semantic Web and in Digital Humanities. In FIN-CLARIAH our goal is to make selected results of this work available to external users along the following pipeline and compoments outlined below. The work starts step-by-step from more mature software tools and services that have already been used in our earlier research projects.
We hope that most mature parts of the infrastructure, linked data, and applications, now maintained by the Semantic Computing Research Group (SeCo) at the Aalto University and University of Helsinki, will be gradually deployed by the data owners and users in the Finnish Cultural Heritage sector, such the National Archives, Finnish Literature Society, Finnish Heritage Agency, Finnish Institute for Languages, National Library, Ministry of Justice, and Parliament of Finland. Data from these organizations and others have been enriched, linked, and published at the Linked Data Finland platform, and used in the Sampo portals in use in Finland. Finding sustainable solution for maintaining the services and the underlying infrastructure through work in FIN-CLARIAH would be desirable.
Implementation: Supporting Infrastructure Pipeline and Components
Our work in FIN-CLARIAH falls into several areas that need to be covered in order to create data and services for DH research:
- Speech2Text. Tooling for creating textual time-stamped representations of videos and audio recordings. Here the goal is, e.g., to facilitate preservation of intangible cultural heritage and easy access to it, as in the WarMemoirSampo system that publishes interview memoirs of the veterans of the WW2.
- Image2Text. OCR services developed, e.g., for the historical minutes of the Parliament of Finland in the ParliamentSampo system.
- Text2Knowledge. Finnish language toolkit & web services for linked data knowledge extraction from unstructured Finnish texts, including named entity recognition and linking, automatic keyword annotation, relation extraction, and semantic labeling. This work has been carried out, e.g., in our various systems related to biographical texts, such as BiographySampo and AcademySampo.
- Knowledge2DataAnalysis. Reusable tooling for Digital Humanities on top of a linked data service and SPARQL endpoint, as used in various Sampo systems.
- DataAnalysis2AI. Tooling for knowledge discovery and computational creativity. Here the machine is seen as an intelligent agent searching itself for interesting patterns in knowledge graphs, solving problems, and even explaining the results to the human user (to support "3. generation DH systems" as suggested in this paper).
Infrastructure components to be maintained and built in our part of the FIN-CLARIAH initiative include:
- ONKI ontology services (ONKI.fi) for history, extending the Finto.fi services of the National Library. This work comprises ontologies for historical persons, places, events, times, occupations, and names.
- Historical map services (Hipla.fi). Here historical maps can be aligned with contemporary ones and used as layers in applications, based on the MapWarper tool and linked data for storing related metadata.
- Linked Data Finland (LDF.fi). This platform is used for publihing linked data as services using the standards and best practices of W3C. Our focus here is on using the “7-star” model, extending the classic Tim Berners-Lee's 5-star model, for better reusability and quality of linked datasets.
- Natural language processing toolkit and services for extracting linked data.
- Learning materials Providing the DH community with more educational online material on using linked data, such as developing the Linked Data School Linda .
- Maintaining the Sampo Series of linked open data services and semantic portals in use in Finland
and the Sampo-UI framework for developing Sampo applications. In particular, the following Sampos are initially in focus:
- NameSampo (main data owners: Finnish Institute of Languages, National Survey)
- BiographySampo (main data owners: Finnish Literature Society (SKS), Edita Publishing, and others)
- WarSampo, WarVictimSampo 1914–1922, and WarMemoirSampo (main data owners: National Archives, Defence Forces, Tammenlehvän Perinneliitto ry)
- AcademySampo (main data owners: University of Helsinki Archives, National Archives)
- FindSampo (main data owners: Finnish Heritage Agency, National Museum, British Museum (UK))
- Mapping Manuscript Migrations Sampo (main data owners: Oxford University (UK), Schoenberg Institute (US), IRHT (Paris))
- LetterSampo (main data owners: Huygens Insititute (NL), Berlin-Brandenburg Academy of Sciences (D), Oxford University (UK))
- LawSampo (main data owners: Ministry of Justice, Edita Publishing)
- ParliamentSampo (main data owners: Parliament of Finland, Finnísh Literature Society)
- LetterSampo Finland (main data owners: Various Finnish archives for epistolary data (letters), including National Archives, National Library, National Gallery, Åbo Academy, Finnish Literature Society, Svenska Litteratursällskapet i Finland, and many others)
- OperaSampo (main data owner: Sibelius Academy)
More Information about the Infrastucture
The following short persentation at the DARIAH Annual Meeting 2023 in Budapest gives an overview of our work related to FIN-CLARIAH:
Finnish LOD Infra and Sampo portals, DARIAH Annual Meeting, Budapest, 2023 from SeCo Research Group on Vimeo.
The keynote presentation video of the DCMI 2021 conference below, the related paper How to Create a National Cross-domain Ontology and Linked Data Infrastructure and Use It on the Semantic Web , Digtal Humanities on the Semantic Web: Sampo model and portal series , and other papers listed below overview our work on developing a national Semantic Web infrastructure in Finland and its applications. For a full account of SeCo research on this topic see the SeCo Publications List.
Making National Linked Open Data Services Sustainable
Here is a video (in Finnish) suggesting one way to make the Linked Open Data services and Sampo portals sustainable. Would establishing a joint collaborative Linked Open Data Centre run by the memory organizations be a ferasible solution?
Ehdotus Sampo-portaalien ja -datapalveluiden vakinaistamiseksi from SeCo Research Group on Vimeo.
The FIN-CLARIAH work is funded by the Research Council of Finland under the NextGeneration funding programme of the European Union, as part of the national research infrastructure programme FIRI 2021. The first phase of the initiative lasted 2022-2023 and the second 2024-2025.
Contact
Professor Eero Hyvönen
Aalto University and University of Helsinki (Helsinki Centre for Digital Humanities HELDIG)


