 |
Mapping Manuscript Migrations (MMM)
|
Motivating the Project
Thousands of European pre-modern manuscripts have survived until the present day.
As the primary surviving witnesses to the world of pre-modern Europe they provide crucial evidence for research in many disciplines,
including textual and literary studies, history, cultural heritage, and the fine arts.
As the result of changes of ownership over the centuries, they are now spread all over the world.
They often feature among the treasures of libraries, museums, galleries, and archives, and they are frequently the focus of exhibitions
and events in these institutions. Over the last twenty years there has been a proliferation of digital data relating to these manuscripts,
including catalogues, specialist databases, and numerous collections of digital images.
But there is little in the way of coherent, interoperable digital infrastructure, with the result that large-scale discovery and analysis requires
the time-consuming exploration of numerous disparate resources.
The Mapping Manuscript Migrations project is linking disparate datasets
from Europe and North America to provide an international view of the history and provenance of medieval and Renaissance manuscripts.
The project facilitates humanities researchers to analyse and visualize the aggregated data at scales ranging from individual manuscripts to thousands of manuscripts.
Our research addresses the origins and movements of these manuscripts, and the collectors and owners involved in their history.
The tools developed show how the manuscripts have traveled across time and space to their current locations, where they continue to find new audiences.
See the 15min overview video below of the MMM System and Linked Open Data service in use presented at the ISWC 2021 conference:
Semantic MMM Portal
A key result of the project is the semantic portal demonstrator "Mapping Manuscript Migrations" (MMM).
MMM is a semantic portal intended to enable large-scale exploration of data relating to the history and provenance of (primarily)
Western European medieval and early modern manuscripts.
MMM is based on the "Sampo" model for semantic portals:
The MMM portal enables you to search and browse through the data assembled by the project from distributed heterogenous databases.
The portal data can be studied using multiple application views that are equipped with faceted search and browsing engines integrated
with ready-to-use tools for Digital Humanities research.
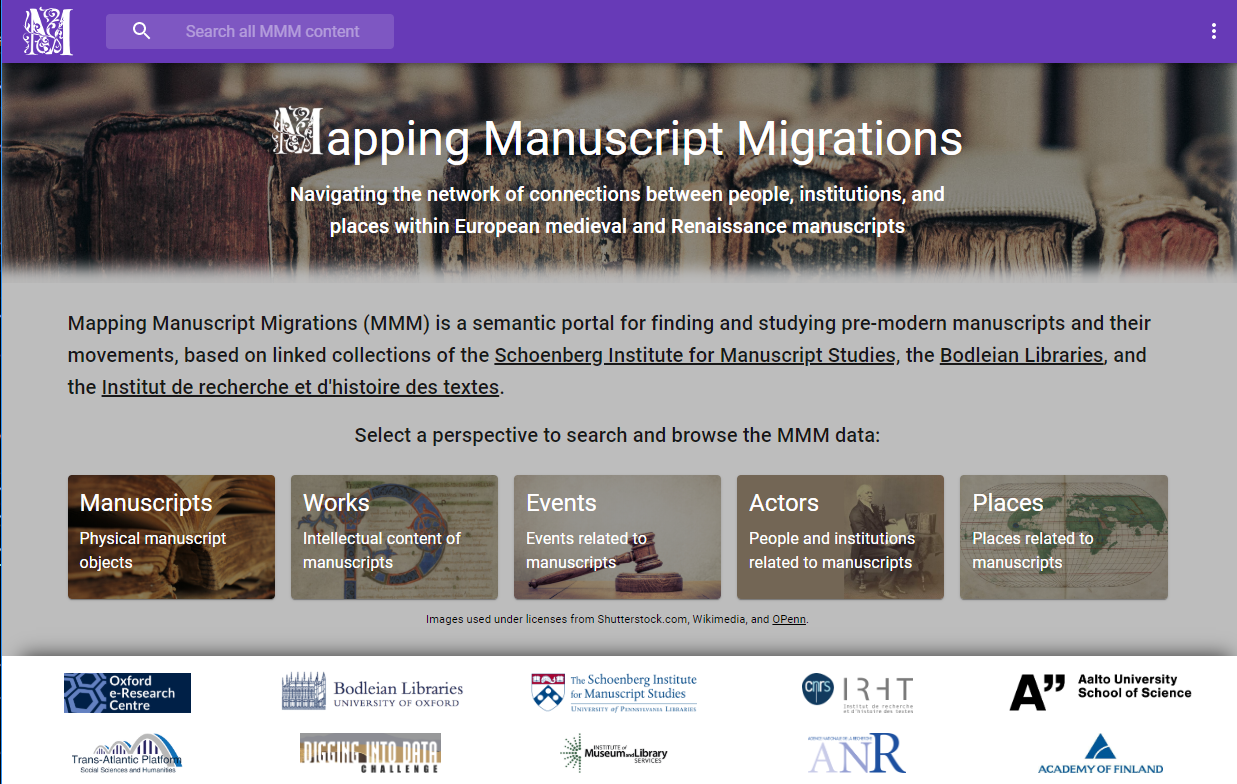
Figure: Landing page of the MMM portal
The portal is available at
https://mappingmanuscriptmigrations.org
released at the Round 4 Conference (2020) of Digging into Data programme, Alexandria, Virginia, USA, January 29-31, 2020.
Linked Open Data
MMM combines data from three specialist databases, based on Linked Open Data principles and technology:
The data have been combined using a set of shared ontologies and a novel unified Data Model that extends the CIDOC-CRM and FRBRoo ontologies.
The original data have not been corrected or amended in any way, only aggregated from the legacy databases and transformed and linked into a
global Knowledge Graph hosted in a linked open data service. The semantic portal MMM was created on top of the data service using its
SPARQL API.
If you notice an error in the data, please report it to the custodians of the original databases.
Data Re-use and Reference
The MMM data are made available for reuse under a CC-BY-NC 4.0 license.
This means: you must give appropriate credit to the data owners and the MMM project, provide a link to the license, and indicate if changes were made;
you may do so in any reasonable manner,
but not in any way that suggests the MMM project or its partner institutions endorses you or your use; you may not use the data for commercial purposes.
For making scientific references, you can refer to the publications listed below.
Data Service Online
The linked data is served by the Linked Open Data service, hosted
at
http://www.ldf.fi/dataset/mmm/
based on the recommendations and best practices of W3C.
If you want to search and re-use all the underlying data using the SPARQL query language, the endpoint is available at:
http://ldf.fi/mmm/sparql
Acknowledgements
Thanks for collaborations to our colleagues at the
University of Oxford: Toby Burrows (PI), David Lewis, Andrew Morrison, Kevin Page, Pip Willcox, Athanasios Velios, and Graham Klyne;
at
Institut de recherche et d’histoire des textes (IRHT): Hanno Wijsman (PI), Nicole Bergk Pinto, Antoine Brix, Mahaut Cazals, Alexandre Gaudin, Synnøve Myking, Pierre-Louis Pinault, and Guillaume Porte;
and at the
University of Pennsylvania: Lynn Ransom (PI), Doug Emery, Mitch Fraas, Benny Heller, and Emma Thomson.
The Mapping Manuscript Migrations project was funded under Round 4 of the Trans-Atlantic Platform’s Digging into Data Challenge.
The four project partners were funded by their respective national funding agencies:
Economic and Social Research Council (UK), Agence nationale de la recherche (France), Institute of Museum and Library Services (US), and the Academy of Finland.

Contacts at Aalto University and University of Helsinki (HELDIG)
- Prof. Eero Hyvönen (PI), Aalto University and University of Helsinki (HELDIG)
- MSc Esko Ikkala, Aalto University
- Dr. Mikko Koho, Aalto University and University of Helsinki (HELDIG)
- Dr. Jouni Tuominen, University of Helsinki (HELDIG) and Aalto University
For more information, see the MMM project blog.
Technical documentation can be found at https://mapping-manuscript-migrations.github.io/.
Publications
2025
Eero Hyvönen, Annastiina Ahola, Petri Leskinen and Jouni Tuominen:
SampoSampo: A Portal for Studying Enriched Data and Semantic Connections on a Cultural Heritage Linked Open Data Cloud.
The Semantic Web: ESWC 2025 Satellite Events, Portoroz, Slovenia, June 1 - 5, 2025, Proceedings, Lecture Notes in Computer Science, vol. 15832, pp. 67-74, Springer-Verlag, 2025.
bib pdf link 2024
2023
2022
Mikko Koho, L. P. Coladangelo, Lynn Ransom and Doug Emery:
A Wikibase Model for Premodern Manuscript Metadata Harmonization, Linked Data Integration, and Discovery. August, 2022. Submitted.
bib Esko Ikkala, Eero Hyvönen, Heikki Rantala and Mikko Koho:
Sampo-UI: A Full Stack JavaScript Framework for Developing Semantic Portal User Interfaces. Semantic Web – Interoperability, Usability, Applicability, vol. 13, no. 1, pp. 69-84, January, 2022. Online version published in 2021, print version in 2022.
bib pdf link 2021
Eero Hyvönen, Esko Ikkala, Mikko Koho, Jouni Tuominen, Toby Burrows, Lynn Ransom and Hanno Wijsman:
Mapping Manuscript Migrations on the Semantic Web: A Semantic Portal and Linked Open Data Service for Premodern Manuscript Research.
The Semantic Web - ISWC 2021, Lecture Notes in Computer Science, vol. 12922, pp. 615-630, Springer, 2021.
bib pdf link Toby Burrows, Doug Emery, Arthur Mitchell Fraas, Eero Hyvönen, Esko Ikkala, Mikko Koho, David Lewis, Andrew Morrison, Kevin Page, Lynn Ransom, Emma Cawfield Thomson, Jouni Tuominen, Athanasios Velios and Hanno Wijsman:
A New Model for Manuscript Provenance Research: The Mapping Manuscripts Migrations Project. Manuscript Studies, vol. 6, no. 1, pp. 131-144, The University of Pennsylvania Press, Philadelphia, US, July, 2021.
bib pdf link Toby Burrows, Laura Cleaver, Doug Emery, Mikko Koho, Lynn Ransom and Emma Thomson:
Using SPARQL to investigate the research potential of an aggregated Linked Open Data dataset for the Mapping Manuscript Migrations project. July, 2021. Association for Computers and the Humanities (ACH) conference 2021 abstract.
bib Toby Burrows, Mikko Koho, Jouni Tuominen, Eero Hyvönen, Kevin Page, David Lewis, Doug Emery, Hanno Wijsman, Lynn Ransom and Emma Cawlfield Thomson:
Modelling the History of Medieval and Renaissance Manuscripts for the Mapping Manuscript Migrations Portal.
Data for History 2021: Modelling Time, Places, Agents, June, 2021. Abstract.
bib link Mikko Koho, Toby Burrows, Eero Hyvönen, Esko Ikkala, Kevin Page, Lynn Ransom, Jouni Tuominen, Doug Emery, Mitch Fraas, Benjamin Heller, David Lewis, Andrew Morrison, Guillaume Porte, Emma Thomson, Athanasios Velios and Hanno Wijsman:
Harmonizing and Publishing Heterogeneous Pre-Modern Manuscript Metadata as Linked Open Data. Journal of the Association for Information Science and Technology (JASIST), vol. 73, no. 2, pp. 240-257, May, 2021.
bib pdf link Manuscripts are a crucial form of evidence for research into all aspects of premodern European history and culture, and there are numerous databases devoted to describing them in detail. This descriptive information, however, is typically available only in separate data silos based on incompatible data models and user interfaces. As a result, it has been difficult to study manuscripts comprehensively across these various platforms. To address this challenge, a team of manuscript scholars and computer scientists worked to create “Mapping Manuscript Migrations” (MMM), a semantic portal, and a Linked Open Data service. MMM stands as a successful proof of concept for integrating distinct manuscript datasets into a shared platform for research and discovery with the potential for future expansion. This paper will discuss the major products of the MMM project: a unified data model, a repeatable data transformation pipeline, a Linked Open Data knowledge graph, and a Semantic Web portal. It will also examine the crucial importance of an iterative process of multidisciplinary collaboration embedded throughout the project, enabling humanities researchers to shape the development of a digital platform and tools, while also enabling the same researchers to ask more sophisticated and comprehensive research questions of the aggregated data.
2020
Toby Burrows, Antoine Brix, Douglas Emery, Arthur Mitchell Fraas, Eero Hyvönen, Esko Ikkala, Mikko Koho, David Lewis, Synnove Myking, Kevin Page, Lynn Ransom, Emma Cawlfield Thomson, Jouni Tuominen, Hanno Wijsman and Pip Wilcox:
Linked Open Data Vocabularies and Identifiers for Medieval Studies.
DHN 2020 Digital Humanities in the Nordic Countries. Proceedings of the Digital Humanities in the Nordic Countries 5th Conference, pp. 211-218, CEUR Workshop Proceedings, vol. 2612, Riga, Latvia, October, 2020.
bib pdf link Toby Burrows, Douglas Emery, Mitch Fraas, Eero Hyvönen, Esko Ikkala, Mikko Koho, David Lewis, Andrew Morrison, Kevin Page, Lynn Ransom, Emma Thomson, Jouni Tuominen, Athanasios Velios and Hanno Wijsman:
Mapping Manuscript Migrations: Digging into Data for Researching the History and Provenance of Medieval and Renaissance Manuscripts: White Paper. August, 2020.
bib pdf link Toby Burrows, Douglas Emery, Arthur Mitchell Fraas, Eero Hyvönen, Esko Ikkala, Mikko Koho, David Lewis, Andrew Morrison, Kevin Page, Lynn Ransom, Emma Cawlfield Thomson, Jouni Tuominen, Athanasios Velios, and Hanno Wijsman:
Mapping Manuscript Migrations Knowledge Graph: Data for Tracing the History and Provenance of Medieval and Renaissance Manuscripts. Journal of Open Humanities Data, vol. 6, pp. 3, June, 2020.
bib pdf link 2019
Eero Hyvönen, Esko Ikkala, Jouni Tuominen, Mikko Koho, Toby Burrows, Lynn Ransom and Hanno Wijsman:
A Linked Open Data Service and Portal for Pre-modern Manuscript Research.
DHN 2019 Digital Humanities in Nordic Countries. Proceedings of the Digital Humanities in the Nordic Countries 4th Conference, pp. 220-229, CEUR Workshop Proceedings, Vol-2364, Copenhagen, Denmark, March, 2019.
bib pdf link 2018

